SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
The 8 little cores that could
Each core is pretty small, as it has only one pipeline, no Branch Prediction Unit, no OOO buffers, and no OOO pipeline stages, which search for independent instructions. Only the large register file and thread select logic make the very simple core a bit fatter and more complex.
An 8 KB data cache and 16 KB instruction cache give an L1-hitrate of 90% or less, but it also helps to keep each core small. To keep 8 cores with such tiny L1-caches running at 70% efficiency with so many threads, a big L2-cache and massive memory bandwidth is needed.
We have quantified this effect of faster cache coherency in our Linux database server article. A dual core Opteron was about 13% faster than two single core CPUs at the same clock speed. With 8 cores that might share data, cache coherency has an even bigger impact on performance. Sharing the L2-cache also ensures that no coherency traffic is necessary on the level 2 cache.
There is more. Each core has a modular arithmetic unit (MAU) that supports modular multiplication and exponentiation to speed up Secure Sockets Layer (SSL) processing. This compensates for the lack of the FPU and the low clock speed. A single 1.2 GHz MAU seems to "sign" as fast as a 1.8 GHz Opteron, but quite a bit slower at verifying authenticity.
Each core is pretty small, as it has only one pipeline, no Branch Prediction Unit, no OOO buffers, and no OOO pipeline stages, which search for independent instructions. Only the large register file and thread select logic make the very simple core a bit fatter and more complex.
An 8 KB data cache and 16 KB instruction cache give an L1-hitrate of 90% or less, but it also helps to keep each core small. To keep 8 cores with such tiny L1-caches running at 70% efficiency with so many threads, a big L2-cache and massive memory bandwidth is needed.
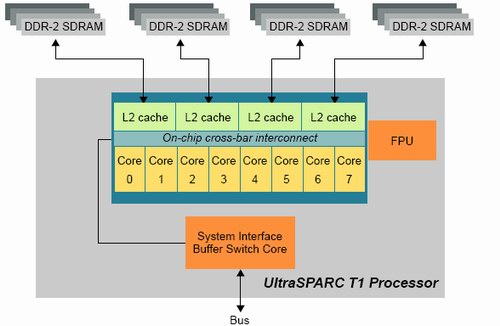
Fig 5: 8 cores fed by a 3 MB L2-cache and 4 integrated memory controllers. Source:SUN.
We have quantified this effect of faster cache coherency in our Linux database server article. A dual core Opteron was about 13% faster than two single core CPUs at the same clock speed. With 8 cores that might share data, cache coherency has an even bigger impact on performance. Sharing the L2-cache also ensures that no coherency traffic is necessary on the level 2 cache.
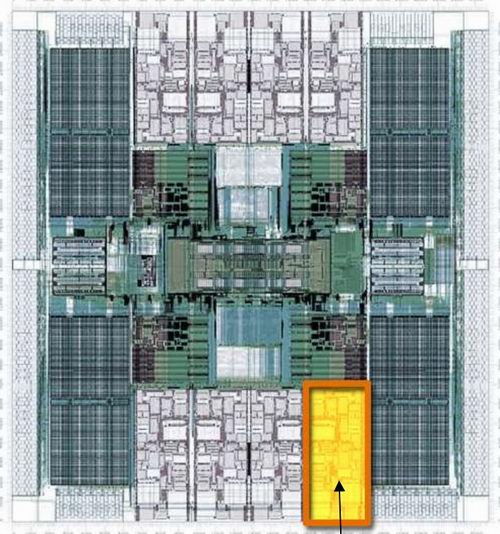
Fig 6: One (yellow) of the 8 cores (gray) of the T1. Source:SUN.
As a rough guideline, performance degrades if the number of floating-point instructions exceeds 1 percent of total instructions.Some instructions like division have long latencies, causing the thread to be skipped. The situation is then similar to a thread with a long latency load. To keep power consumption and die size per core low, each core has a very shallow six-stage pipeline: fetch, thread select, decode, execute, memory, and write back. The result is an architecture that does not need branch prediction, thanks to a shallow pipeline and FMT. However, this limits clock speed to 1.2 GHz in 90 nm, while competing chips are clocking between 2 and 4 GHz.
There is more. Each core has a modular arithmetic unit (MAU) that supports modular multiplication and exponentiation to speed up Secure Sockets Layer (SSL) processing. This compensates for the lack of the FPU and the low clock speed. A single 1.2 GHz MAU seems to "sign" as fast as a 1.8 GHz Opteron, but quite a bit slower at verifying authenticity.








49 Comments
View All Comments
Betwon - Thursday, December 29, 2005 - link
Why? Really?It shows that the performance of FP apps is very very poor!!!
We can't believe it.
It is terrible for many FP apps.
Now, we know that the new CPU is only for the integer/32-thread-parallel-well apps.
JarredWalton - Friday, December 30, 2005 - link
How many FP instructions do you think a high-end web server runs? Try to think outside the box for a minute, rather than comparing it to HPC-oriented chips. Itanium wastes more than 80% of it's potential when running many database loads, and it does better than some of the other alternatives. Spending lots of die space on OOO logic and long pipelines isn't always the best solution, especially if you can guarantee that most code will have many threads. Quit thinking Half-Life and other games for a minute and try to shift to the big iron server world.Betwon - Friday, December 30, 2005 - link
Only one FP unit? not less than 40 cycles latency?If it is true:
The new CPU will be slower than P3@450MHz in the area of FP apps.
Brian23 - Friday, December 30, 2005 - link
who cares. That's not what it's designed to do. The only reason that it has the floating point core is for the rare occation when a FP op is needed.Betwon - Friday, December 30, 2005 - link
It means that this new CPU does not fit for the FP apps. Maybe a old CPU(10 years old) can beat it.Now, we know that the apps-area of this new CPU is very very spec...
It is too difficult to find apps(2-thread-paralle-well or more) for P4, how to find the apps(32-thread-paralle-well) easily?
thesix - Friday, December 30, 2005 - link
Betwon,You seem to be confused with the concept of multi-threading v.s. multi-tasking.
You do NOT need to find an app that runs 32 parallel threads in one process.
You can simple run 32 _instances_ of that app, for example,
or, run 32 different apps even if everyone of them is single-threaded.
A typical server environment is just like that.
When we talk about Chip Multi-Threading (CMT), it's the _hardware_ thread, which is a totally different concept than software thread. Once hardward thread represents the capability of running one computing task, it does care where this task comes from the same app/process or not.
A perfect example is the Apache webserver, IIRC, at least in version 1.x.y (which is still the most popular version), the apache http server process is single-threaded. A new process is forked for each (or a group of) new http request. The more hardware threads you have, the more requests you can handle in parallel. Of course, the faster each hardward thread (or core, or cpu) is, the more requests it can handle in a given amount of time, but not in parallel.
It is also true that _most_ database out there doesn't use _any_ floatpoint computation.
So, if you think about it, the market for T1 type of CPU/server is not a small one.
The bottom line is, T1 excels at througput/Watt and througput/chip.
It's a well kown fact that it sucks at single-task or floatpoint computation.
Betwon - Friday, December 30, 2005 - link
NO!You seem to be confused with the concept of SMT v.s. CMT.
It is very low efficient, if T1 only use CMT but not use SMT.
T1 have no branch prediction and one_inst_issue/core, very very poor FP performacne.
The only explain about how to improve the efficiency(very poor) is to use SMT to hide the latency(by branch miss/cache miss ect.)
But it has only 8KB L1(which will be used by 4 threads), the cache miss will increase. It is possible to become worst.
thesix - Friday, December 30, 2005 - link
Explain to me the conceptual difference between SMT and CMT?All you have said is the (component) _implementation_ difference between T1 and POWER in achieving hardware threading.
Since you appear to know this topic quite well, why the ignorant comment like this:
"It is too difficult to find apps(2-thread-paralle-well or more) for P4, how to find the apps(32-thread-paralle-well) easily?"
and kept screaming about the lack of floatpoint performance?
I simply don't understand why you're so upset.
Betwon - Friday, December 30, 2005 - link
My english has some problem.I think that T1 use both CMT and SMT.
SMT -- one core with four threads
CMT -- one CPU with eight cores
If without SMT, cores of T1 will be very poor efficient (because of the stall's latency caused by branch miss/cache miss).
The very very poor FP performance of T1 is the truth.
We have to remind ourselves that it is only a integer CPU. It's FP performance is too terrible.
fitten - Sunday, January 1, 2006 - link
There is no "reminding" anyone of the poor FPU performance. The thing was never designed to be strong in FPU (quite obviously). It has "enough" FPU so that it doesn't have to do software emulation and that's it. So... going on and on about FPU performance is a useless argument here. Sun (nor anyone talking about the T1s) has ever said that it would be good at FPU perforamnce because it wasn't designed to be.This CPU was designed for servers. Servers typically have high cache miss rates anyway because of a number of things (streaming any kind of I/O doesn't have much data locality advantages). Server processes also typically have lots of I/O stalls. When a context stalls, each core has multiple other contexts to chose from in order to keep running.
So, I think the points you are trying to stress are quite obvious from the design of the CPU and the types of loads it was designed to handle. Yes, poor FPU performance obvious from having very limited (and slow) FPU resources. Yes, if you aren't running lots of threads the machine is inefficient because the thing is designed to take advantage of server type threads where there will be lots of I/O stalling and if there is nothing else to run while waiting on the I/O requests to finish, it sits idle (much like any other machine). Yes, in-order execution and the lack of branch prediction will not mask any stalls the instruction stream will generate (which is OK because the design of the CPU actually counts on these stalls to happen so that lots of nice SMT can happen).
It sounds like you are in violent agreement with everyone :)