ASUS ROG Rampage Formula: Why we were wrong about the Intel X48
by Kris Boughton on January 25, 2008 4:30 AM EST- Posted in
- Motherboards
The Clock Crossing Procedure and MCH Read Delay (tRD)
Have you ever stopped to wonder how the Memory Control Hub (MCH) manages to transfer data from the system bus (FSB) to the memory bus and vice versa? Maybe you questioned why it was not possible to run your memory at any speed you desired, independent of the selected FSB. While there have been some chipsets that provide this capability, performance was rather spotty at times depending on the particular settings in use. In fact, these systems often resulted in the creation of rather large ranges of bus speed and memory speed ratios that refused to function, stable or otherwise. The concept was certainly fair enough, but at the time a well-engineered implementation turned out to be far more difficult that anyone may have been willing to concede. It should not come as a surprise that Intel chipsets have only allow the use of certain validated memory ratios - those same numbers we have grown to love (or hate) like 1:1, 5:4, 3:2, and so forth.
Back in the days of relatively slow-paced memory performance improvements, Intel had no problems pumping out processors with default FSB values that made running memory at synchronous speeds an expensive proposition. Thus they created the "down" divider that allowed the memory subsystem to run at a bus speed below that of the system bus. This allowed for a period of innovation where processor bus architecture was able to improve without placing an undue burden on the memory industry to create reasonably priced modules capable of these increased speeds.
In a lot of ways this also prevented cost-prohibitive aspects of validating higher data transfer rates from ultimately affecting the market as a whole. Because Intel was not obligated to allocate additional funding for the completion of this expensive process, the savings (however small) could be passed on to the consumer. When coupled with the added benefit of allowing for the purchase and use of lower-binned memory, we can easily see why a move such as this helped stimulate the industry into a period of unprecedented growth.
Today's market is much different. Older signaling technologies like Advanced Gunning Transceiver Logic (AGTL+), used almost exclusively by Intel in their monolithic CPU-to-MCH interface architecture, have just about reached the practical limits. As such, "up" dividers, those that allow for memory bus speeds in excess of the system bus speed, are used almost exclusively by high-performance systems. Indeed, it would be hard to imagine ever being satisfied with a system able to make use of memory operating at transfer rates of up to DDR2-667, and no higher. As odd as it may seem, the next generation of memory (DDR3) is based entirely on the concept of running at speeds mandating the use of at least a 2:1 memory bus to system bus frequency ratio.
When examined from this aspect it becomes clear what DDR3 really is - an early look at the next generation's mainstream memory component. Only when Intel has removed the performance barrier of their antiquated FSB and loosely-coupled MCH will we be fully able to finally experience the real improvements that DDR3 promises to provide. But we digress - speculating about what could have been done better or things to come is trite. Instead, let's concentrate on what can be done now to improve the collective performance of our systems.
Below is a somewhat basic representation of the problem at hand (and later we will introduce the fairly elegant solution that Intel has crafted in order to tackle said problem). Are you still wondering what the problem is? Put briefly: designing an effective means for transferring data from one bus "domain" to the other, while still respecting the timing requirements for each bus.
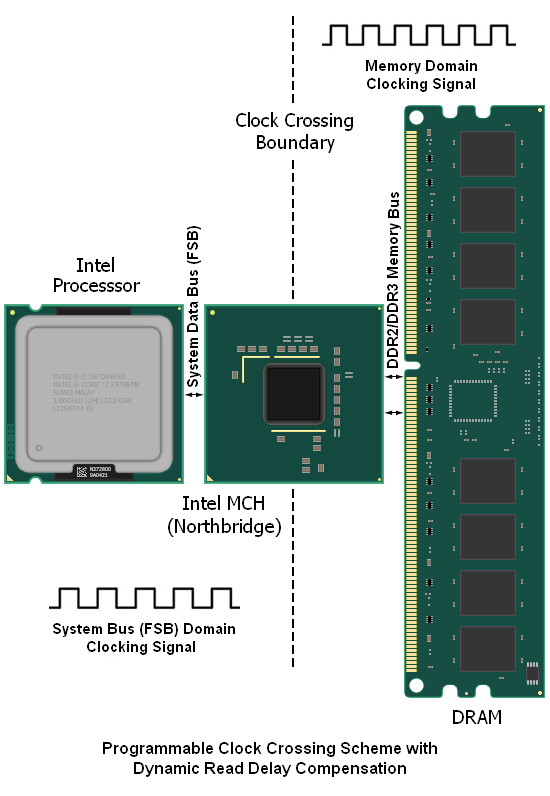
We made mention earlier that we believe Intel's solution to be quite elegant. While this is true, the system is still far from perfect as it introduces a significant amount of extra data access latency to each and every memory read request. It might seem ironic that the design initially constructed in order to allow for higher memory speeds ends up being the very reason for the additional latency penalty incurred, but this is the case. Coincidentally, we can apply a similar accounting of the system's flaws when explaining why actualized system performance improvements are always far less than predicted when making use of the larger dividers.
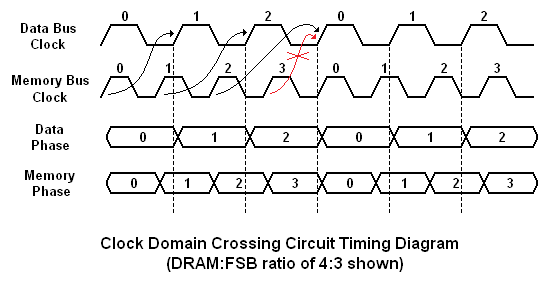
Moving data between two simultaneously running parallel buses requires a fine level of timing control and a fair amount of programmable logic to be successful, especially if the scheme is to remain flexible. The graphic below should help to illustrate the concept. Four memory data clock cycles for every three system data bus cycles (a 4:3 DRAM:FSB memory ratio) means that the MCH can do little more than queue up data requested from the memory for transport to the system bus.
This process works to ensure that no FSB cycles are left unused, but it does little to improve actual memory throughput. Because of this, the gains seen are largely due to the increased transfer efficiency. For the same reason, sustained data rates, while improved, are made at the expense of requiring added latency associated with the transfer scheme. This has the affect of retarding the responsiveness of short bursts of random read activity. Some users [Ed: Androids in disguise?] even swear that they can tell when they are using an Intel system because of the suppression of the "snappy" experience that comes when using true low-latency systems.
In order to better quantify exactly how the MCH clock crossing procedure influences system performance, it might be helpful to take a step back and examine the different component parameters that contribute to a system's overall memory read (access) latency. The diagram below helps to illustrate just this point - we have identified each distinct operation that takes place during a CPU data request and the sum of the individual latencies that involved with each part of the process make up the total system memory access latency, as measured. As we will see, this time - expressed in nanoseconds (ns) - is critical to overall system performance.
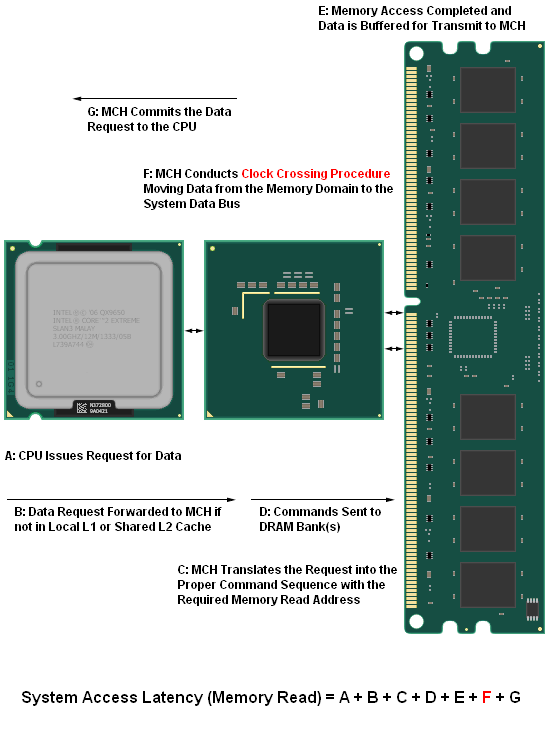
Although the user has at least minor control over just about every aspect of the system as modeled above, there are a few settings that when altered have the potential to drastically impact performance for the better (or worse, depending on how well you understand what you are doing). One of the most well known is the selection of primary memory timings (tCL-tRCD-tRP-tRAS). You may be surprised to learn that the effect of properly setting these values, represented by part "E", is quite insignificant when compared to your choice of tRD (the singular consideration in developing the latency associated with part "F"). This will be our focus for the remainder of our discussion. We have already lightly touched on this mysterious setting on the prior page.








73 Comments
View All Comments
dallas - Monday, March 24, 2008 - link
I was wondering how this chipset and Windows Vista 64-bit handles IRQ ? I have a Creative X-fi and it has had a lot of problems with PCI-latency and shared IRQ. According to the manual PCI slot 2 is the only one of the two that does not share IRQ with the graphic cards. Do you guys have any experience of this ?Second question is related also to IRQ. I have a Razer Deathadder mouse which I use at 1000Hz polling rate and it seems to cause quite a bit CPU-usage (average of 10% with AMD64 3500+ when moving mouse at desktop without overlapping anything). I guess it would be ideal to connect it to a USB-port not sharing any IRQ. Rampage Formula has 12 USB-ports total, but reading the manual it says there is USB controllers 1 to 6 and USB 2.0 controllers 1 and 2. How do I relate these figures to the actual layout of the board ? USB controllers 2 and 5 are the only ones not sharing IRQ.
http://dlsvr01.asus.com/pub/ASUS/mb/socket775/Ramp...">http://dlsvr01.asus.com/pub/ASUS/mb/soc...rmula/Ra...
Thanks
nitemareglitch - Friday, March 7, 2008 - link
My older DFI nForce 4 board had fully adjustable tRd among other things. Asus taking a play from their book?rge - Monday, February 18, 2008 - link
Granted I am using gigabyte p35 dq6 board, but I thought loadline simply was a sensor adjustment? Anyone know what is meant by induced power instabilities? measured by?I thought (and may well be wrong) that with loadline disabled, if I choose 1.25v bios as vcore, idle would be 1.23 volts (Voffset), load (dual core) would be 1.22v (Vdroop), when load stops, overshoot to 1.25v before decreasing back to 1.23 idle. Thus when you are choosing 1.25 volts in bios, you are choosing max volts ie, overshoot max, and not idle volts.
I thought loadline was simply a ~.02v sensor calibration, so when enabled, and you choose 1.25 volts in bios, you are then choosing the idle volts (instead of overshoot max) and thus it idles at 1.25V. During load you still see vdroop to 1.24v, and overshoots to 1.27v.
In other words no difference between loadline enabled 1.23v and loadline disabled 1.25v, just personal preference of making bios vcore set idle volts or max overshoot volts.
If I am wrong can someone please inform me what loadline is, and what is meant by power instabilities...mean ?greater fluctuations in volts or what?
Nickel020 - Saturday, February 16, 2008 - link
Firstly, great article! Got me a long way in increasing my memory speed and understanding the underlying factors.What I don't understand though is why the X48 is better than the X38. I already have the option to change tRD on my Gigabyte P35 DQ6, and I'm getting much better memory perfromance after manually setting it to 6.
As I see it, the option to adjust tRD is only a BIOS issue and it can be done on P35 and X38, so how does this make the X48 a better chipset?
kjboughton - Sunday, February 17, 2008 - link
The difference comes in the voltages required to run equivalent speeds/tRD settings. In fact, the X48 board are capable of running stable at much higher speeds, using tigher MCH Read Delay (tRD) values at lower voltages. More to come soon...Holmer - Monday, February 18, 2008 - link
Thanks for an excellent article.I would just love to know how well the Rampage formula handles overclocking with 4x1 GB RAM? How large is the performance hit as compared to 2x2 GB and can it handle 1200 MHz (with two 2x1 GB kits rated at this speed).
Roughly when can we expect the loon awaited X48 roundup?
Thanks a lot on beforehand.
Holmer - Friday, February 22, 2008 - link
Another question: Is is possible to manually set tRFC > 42 in BIOS? If yes what is the maximun value of tRFC?I would be very grateful for an answer.
The Ghost - Saturday, February 2, 2008 - link
With 400Mhz, tRD of 4, CL of 4 and 3:2 ratio I get this:1,334 > 1,333
Is that enough to post or is 0,001 to little to "allowed" ?
Vikendios - Wednesday, January 30, 2008 - link
It's all very fine, but as long as ATI/AMD GPU's are outclassed by Nvidia's, the gamer scene which drives the $300+ motherboard business has little interest in non-Nvidia-SLI solutions. It's bizarre that Intel focuses on chipsets that can apparently only handle well (correct me if I'm wrong) their arch-competitors AMD's GPU's in (Crossfire) arrays.Intel should hurry to develop competitors to 790i that are really neutral as to which twinned or tripled video cards are used.
Gary Key - Wednesday, January 30, 2008 - link
The last time I tested it, X38 ran SLI faster than 680i. The problem is not the chipset, it is simply a decision by NVIDIA (and/or Intel) not to "officially" license SLI on the Intel chipset platforms, except for the upcoming Skulltrail board.This whole SLI/Crossfire debate has gone on long enough, the technologies accomplish the same purpose (are practically identical from a technological viewpoint) and setting up a board/BIOS to run either is actually very easy. CF runs just fine on the NV680i/780i and SLI runs just fine on the 975X/X38/X48 if driver support is present and the proper switches are enabled in the BIOS. Personally, I would like to have the ability to run (unhindered) AMD or NVIDIA GPUs in multi-GPU configurations on either chipset platform. I just wish they would let the market determine the best multi-GPU solution, but that is pie in the sky thinking. ;)