ASUS ROG Rampage Formula: Why we were wrong about the Intel X48
by Kris Boughton on January 25, 2008 4:30 AM EST- Posted in
- Motherboards
Real-World Results: What Does a Lower tRD Really Provide?
Up until this point we have spent a lot of time writing about the "performance improvement" available by changing just tRD. First, let's define the gain: lower tRD settings result in lower associated TRD values (at equivalent FSB clocks), which allow for a lower memory read latency time, ultimately providing a higher memory read speed (MB/s). Exactly how a system tends to respond to this increase in available bandwidth remains to be seen, as this is largely dependent on just how sensitive the application/game/benchmark is to variations in memory subsystem performance. It stands to reason that more bandwidth and lower latencies cannot possibly be a bad thing, and we have yet to encounter a situation in which any improvement (i.e. decrease) in tRD has ever resulted in lower observed performance.
EVEREST - a popular diagnostics, basic benchmarking, and system reporting program - gives us a means for quantifying the change in memory read rates experienced when directly altering tRD though the use of its "Cache & Memory Benchmark" tool. We have collected these results and present them below for your examination. The essential point to remember when reviewing these figures is that all of this data was collected using memory speeds and settings well within the realm of normal achievement - an FSB of 400MHz using a 5:4 divider for DDR2-1000 with 4-4-4-10 primary timings at a Command Rate of 2N. The only change made between data collection runs was a modification to tRD.
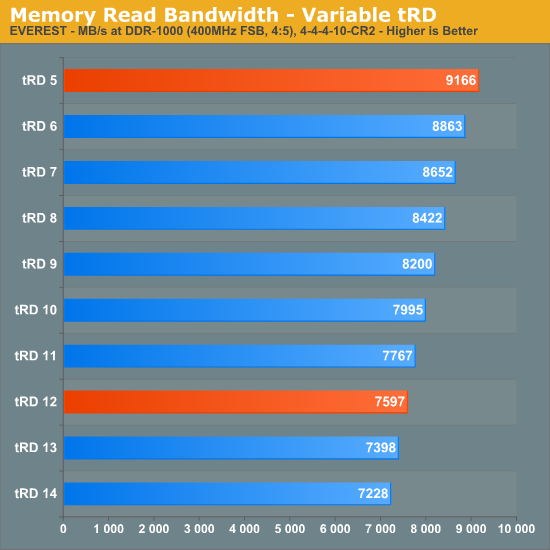
Using the default tRD of 12, our system was able to reach a maximum memory read bandwidth value of 7,597 MB/s - a predictable result considering the rather relaxed configuration. Tightening tRD all the way to a setting of 5 provides us with dramatically different results: 9,166 MB/s, more than 20% higher total throughput! Keep in mind that this was done completely independent of any memory setting adjustment. There is a central tenet of this outcome: because the MCH is solely responsible for delivering the additional performance gains, this concept can be applied to any system, regardless of memory type or quality.
The next graph shows how memory access (read) latency changes with each tRD setting. As we can see, the values march steadily down as we continue to lower tRD. We can also note that the change in latency between any two successive steps is always about 2.5ns, the Tcycle value for 400MHz FSB and the expected equivalent change in TRD for a drop in tRD of one. No other single memory-related performance setting has the potential to influence a reduction in read latency of this magnitude, not even the primary memory timings, making tRD unique in this respect. For this reason, tRD is truly the key to unlocking hidden memory performance, much more so than the primary memory timings traditionally associated with latencies.

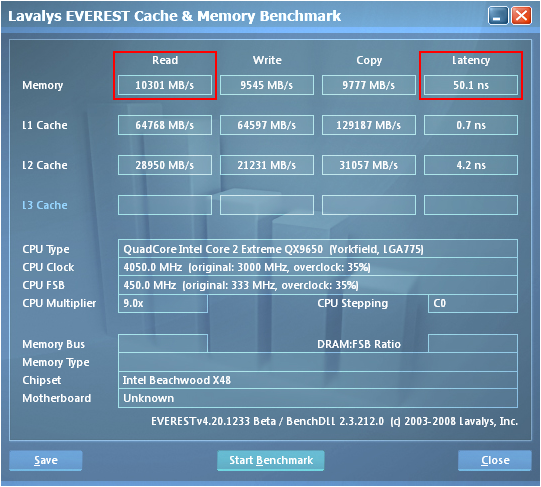
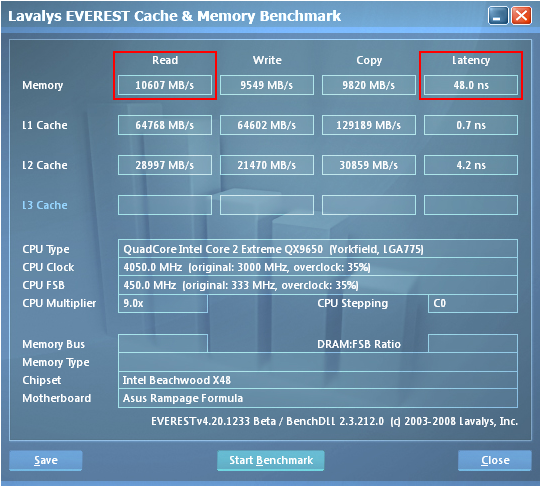
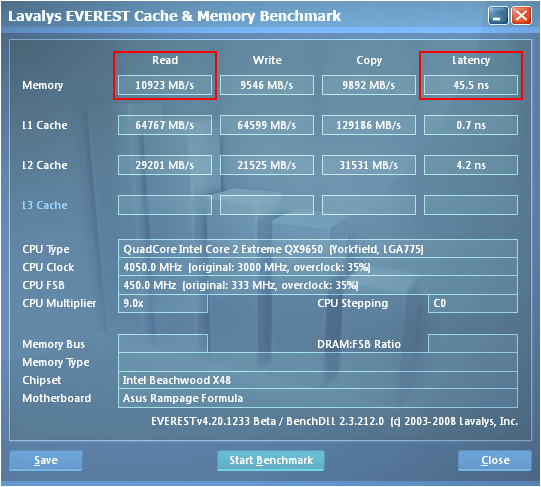
We realized our best performance by pushing the MCH well beyond its specified range of operation. Not only were we able overclock the controller to 450MHz FSB but we also managed to maintain a tRD of 5 (for a TRD of about 11.1ns) at this exceptional bus speed. Using the 3:2 divider and loosening the primary memory timings to 5-5-5-12 allowed us to capture some of the best DDR2 memory bandwidth benchmarks attainable on an Intel platform. As expected, our choice of tRD plays a crucial role in enabling these exceptional results. Screenshots from EVEREST show just how big a difference tRD can make - we have included shots using tRD values of 7, 6, and 5.
A considerable share of the memory read performance advantage that AMD-based systems have over Intel-based systems can be directly attributed to the lower memory latency times made possible by the design of the AMD processor's on-die memory controller. So far we have done a lot to show you why reducing TRD to a lower level can make such a positive impact on performance; knowing this you might tend to believe that the optimal value would be about zero, and you would be right. Eliminating the latency associated with the MCH Read Delay would further reduce total system memory read latency by another 12.5ns (as modeled by the results above).
Given this, Intel-based systems would perform memory read operations about on par with the last generation AMD-based systems. Although not the only reason, this is one of the main motivations behind Intel's decision to finally migrate to a direct point-to-point bus interface not unlike that which has been historically attributed to AMD. Removing the middleman in each memory access operation will do wonders for performance when Intel's next step in 45nm process technology, codenamed Nehalem, hits the shelves in ~Q4'08. Until then we'll have to try to do the best with what we've got.








73 Comments
View All Comments
dallas - Monday, March 24, 2008 - link
I was wondering how this chipset and Windows Vista 64-bit handles IRQ ? I have a Creative X-fi and it has had a lot of problems with PCI-latency and shared IRQ. According to the manual PCI slot 2 is the only one of the two that does not share IRQ with the graphic cards. Do you guys have any experience of this ?Second question is related also to IRQ. I have a Razer Deathadder mouse which I use at 1000Hz polling rate and it seems to cause quite a bit CPU-usage (average of 10% with AMD64 3500+ when moving mouse at desktop without overlapping anything). I guess it would be ideal to connect it to a USB-port not sharing any IRQ. Rampage Formula has 12 USB-ports total, but reading the manual it says there is USB controllers 1 to 6 and USB 2.0 controllers 1 and 2. How do I relate these figures to the actual layout of the board ? USB controllers 2 and 5 are the only ones not sharing IRQ.
http://dlsvr01.asus.com/pub/ASUS/mb/socket775/Ramp...">http://dlsvr01.asus.com/pub/ASUS/mb/soc...rmula/Ra...
Thanks
nitemareglitch - Friday, March 7, 2008 - link
My older DFI nForce 4 board had fully adjustable tRd among other things. Asus taking a play from their book?rge - Monday, February 18, 2008 - link
Granted I am using gigabyte p35 dq6 board, but I thought loadline simply was a sensor adjustment? Anyone know what is meant by induced power instabilities? measured by?I thought (and may well be wrong) that with loadline disabled, if I choose 1.25v bios as vcore, idle would be 1.23 volts (Voffset), load (dual core) would be 1.22v (Vdroop), when load stops, overshoot to 1.25v before decreasing back to 1.23 idle. Thus when you are choosing 1.25 volts in bios, you are choosing max volts ie, overshoot max, and not idle volts.
I thought loadline was simply a ~.02v sensor calibration, so when enabled, and you choose 1.25 volts in bios, you are then choosing the idle volts (instead of overshoot max) and thus it idles at 1.25V. During load you still see vdroop to 1.24v, and overshoots to 1.27v.
In other words no difference between loadline enabled 1.23v and loadline disabled 1.25v, just personal preference of making bios vcore set idle volts or max overshoot volts.
If I am wrong can someone please inform me what loadline is, and what is meant by power instabilities...mean ?greater fluctuations in volts or what?
Nickel020 - Saturday, February 16, 2008 - link
Firstly, great article! Got me a long way in increasing my memory speed and understanding the underlying factors.What I don't understand though is why the X48 is better than the X38. I already have the option to change tRD on my Gigabyte P35 DQ6, and I'm getting much better memory perfromance after manually setting it to 6.
As I see it, the option to adjust tRD is only a BIOS issue and it can be done on P35 and X38, so how does this make the X48 a better chipset?
kjboughton - Sunday, February 17, 2008 - link
The difference comes in the voltages required to run equivalent speeds/tRD settings. In fact, the X48 board are capable of running stable at much higher speeds, using tigher MCH Read Delay (tRD) values at lower voltages. More to come soon...Holmer - Monday, February 18, 2008 - link
Thanks for an excellent article.I would just love to know how well the Rampage formula handles overclocking with 4x1 GB RAM? How large is the performance hit as compared to 2x2 GB and can it handle 1200 MHz (with two 2x1 GB kits rated at this speed).
Roughly when can we expect the loon awaited X48 roundup?
Thanks a lot on beforehand.
Holmer - Friday, February 22, 2008 - link
Another question: Is is possible to manually set tRFC > 42 in BIOS? If yes what is the maximun value of tRFC?I would be very grateful for an answer.
The Ghost - Saturday, February 2, 2008 - link
With 400Mhz, tRD of 4, CL of 4 and 3:2 ratio I get this:1,334 > 1,333
Is that enough to post or is 0,001 to little to "allowed" ?
Vikendios - Wednesday, January 30, 2008 - link
It's all very fine, but as long as ATI/AMD GPU's are outclassed by Nvidia's, the gamer scene which drives the $300+ motherboard business has little interest in non-Nvidia-SLI solutions. It's bizarre that Intel focuses on chipsets that can apparently only handle well (correct me if I'm wrong) their arch-competitors AMD's GPU's in (Crossfire) arrays.Intel should hurry to develop competitors to 790i that are really neutral as to which twinned or tripled video cards are used.
Gary Key - Wednesday, January 30, 2008 - link
The last time I tested it, X38 ran SLI faster than 680i. The problem is not the chipset, it is simply a decision by NVIDIA (and/or Intel) not to "officially" license SLI on the Intel chipset platforms, except for the upcoming Skulltrail board.This whole SLI/Crossfire debate has gone on long enough, the technologies accomplish the same purpose (are practically identical from a technological viewpoint) and setting up a board/BIOS to run either is actually very easy. CF runs just fine on the NV680i/780i and SLI runs just fine on the 975X/X38/X48 if driver support is present and the proper switches are enabled in the BIOS. Personally, I would like to have the ability to run (unhindered) AMD or NVIDIA GPUs in multi-GPU configurations on either chipset platform. I just wish they would let the market determine the best multi-GPU solution, but that is pie in the sky thinking. ;)