The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
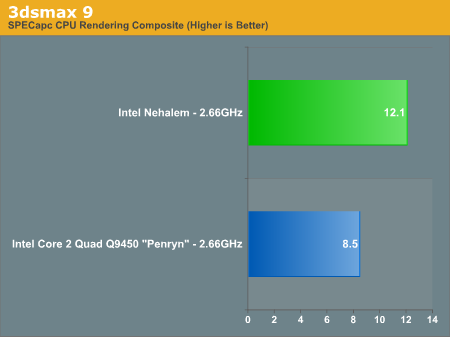
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
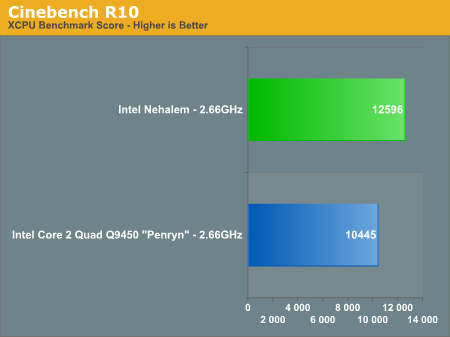
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
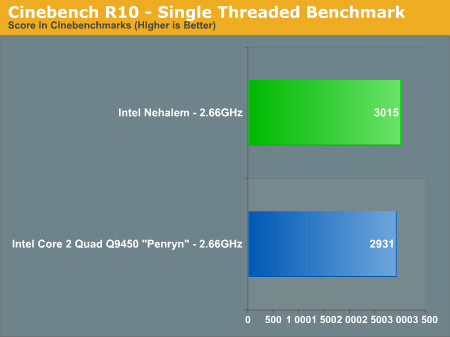
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
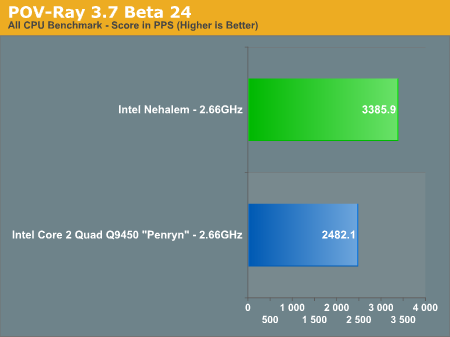
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.








108 Comments
View All Comments
mkruer - Thursday, June 5, 2008 - link
Not a problem.I tend not to take most things at face value. Looking at the Nehalem, its focus was to increase the multi threaded performance, not the single thread app per say. This would put it more inline with what AMD is offering on per core scalability. The Nehalem will get Intel back into the big iron scalability that it lost to AMD.
My guess is that the Nehalem will not give users any real advantage playing games or other single threaded apps, unless the game or app supports more then one thread.
The final question is poised back to AMD. If AMD gets their single threaded IPC and clock speed up, then both platforms should be near identical from a performance standpoint. Then it is just down to price, manufacturing and distribution. I just hope that AMD claims of 15-20% improvement in per core IPC are true. This should make this holiday season much more interesting.
Anand Lal Shimpi - Thursday, June 5, 2008 - link
Nehalem most definitely had a server focus coming up, but I wouldn't underestimate what the IMC will do for CPU-bound gaming performance. Don't forget what the IMC did for the K8 vs. Athlon XP way back when...As far as AMD goes, clock speed issues should get resolved with the move to 45nm. The IPC stuff should get taken care of with Bulldozer, the question is when can we expect Bulldozer?
JumpingJack - Saturday, June 7, 2008 - link
Don't count on 45 nm clocking up much higher than 65 nm, maybe another bin or so.... gate leakage and SCE are limiting and the reason for the sideways move from 90 to 65 nm to begin with (traditional gate ox, SiO2, did not scale 90 to 65 nm) ... the next chance for a decent clock bump will come with their inclusion of HKMG. Which from the rumor mill isn't until 1H09.fitten - Friday, June 6, 2008 - link
AMD hasn't really resolved any clock speed issues from the move from 130nm -> 90nm -> 65nm (look at the top speed 130nm parts compared to the top speed 65nm parts). During some of those transitions, the introductory parts actually were slower clocked than the higher clocked of the previous process and didn't even catch up for some time.bcronce - Thursday, June 5, 2008 - link
Does anyone know why Intel is claiming NUMA on these? I'm assuming you need a multi-cpu system for such uses, but how is the memory segmented that it's NUMA?bcronce - Thursday, June 5, 2008 - link
Seems Arstechnica(http://arstechnica.com/articles/paedia/cpu/what-yo...">http://arstechnica.com/articles/paedia/...-you-nee... has info on NUMA.Assuming more than 1 node being used, each node connects to the Memmory hub and gets assigned it's own *default* memory bank. A one node computer won't see any diff, but a 2-4 node will get a default memory bank and reduced latencies. A node can interleave the data amoung the 2-4 memory banks, but DDR3 is freak'n fast and probably best just streaming from your own bank to reduce contention amoung the nodes.
RobberBaron - Thursday, June 5, 2008 - link
I think there are going to be other issues revolving around this chip. For example:http://www.fudzilla.com/index.php?option=com_conte...">http://www.fudzilla.com/index.php?optio...amp;task...
Nvidia's Director or PR, Derek Perez, has told Fudzilla that Intel actually won't let Nvidia make its Nforce chipset that will work with Intel's Nehalem generation of processors.
We confirmed this from Intel’s side, as well as other sources. Intel told us that there won't be an Nvidia's chipset for Nehalem. Nvidia will call this a "dispute between companies that they are trying to solve privately," but we believe it's much more than that.
AmberClad - Thursday, June 5, 2008 - link
That still leaves you with CrossFire and cards with multiple GPUs like the 9800 X2. It's a tiny fraction of the market that actually uses SLI anyway.Eh, who knows, maybe Nvidia will finally cave and grant that SLI license, and we'll finally have decent chipsets with SLI.
chizow - Thursday, June 5, 2008 - link
Agreed, as much as I love NV GPUs, I'm tired of having SLI tied to NV's buggy chipsets. Realistically I'd probably just get an Intel chipset with Nehalem even if there was an Nforce SLI variant and just go with the fastest single-GPU processor.Baked - Thursday, June 5, 2008 - link
Maybe I can finally grab that E8400 when it drops to $50.