The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
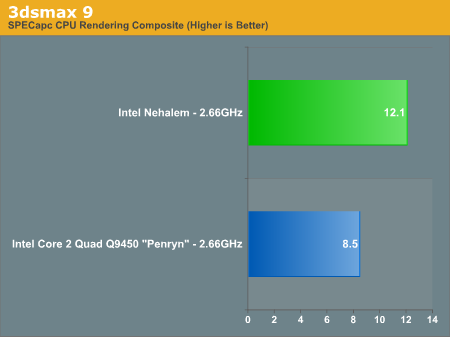
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
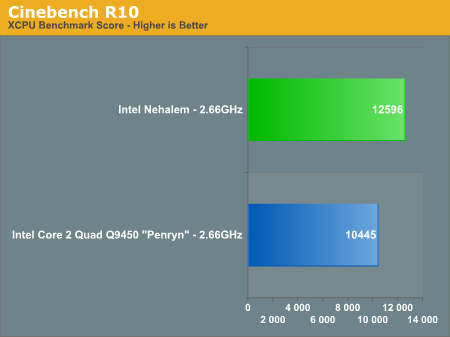
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
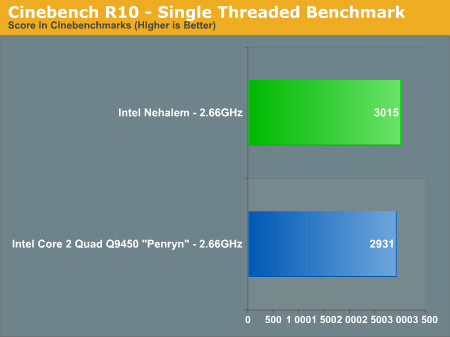
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
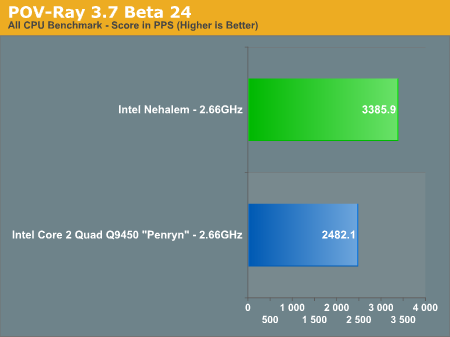
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.








108 Comments
View All Comments
Anand Lal Shimpi - Thursday, June 5, 2008 - link
I really wish I could've turned off hyperthreading :)DivX doesn't scale well beyond 4 threads so that's the best benchmark I could run to look at how Nehalem performs when you keep clock speeds and number of threads capped. With a 28% improvement that's at the upper end of what we should expect from Nehalem on average.
Take care,
Anand
SiliconDoc - Monday, July 28, 2008 - link
Great answer, expalins it to a tee....However that leaves myself and I'd bet most of the fans here with not much real world use for 4x4HT ...
I don't know should we all steal rented DVD's... by re-encoding - only use I know of that might work for the non-connected enduser.
Not like "folding" is all the rage, they would have to pay me to do their work - especially with all the "power savings" hullaballoo going on in tech.
That's great, 28% increase, ok...
So I want it in a 2 core or a single core HT... since that runs everything I do outside the University.
lol
I guess the all core useage all the time, will hit sometime....
Calin - Thursday, June 5, 2008 - link
First of all, the Hyperthreading in the Pentium 4 line brought at most a 20% or so performance advantage, with a -5% or so at worst. I don't have many reasons just now to think this new Hyperthreading would be vastly different.As for the scaling to 8 cores, maybe the scaling was limited due to other issues (latency, interprocessor communication, cache coherency)? It might be possible that DivX on this new platform to increase performance from 4 to 8 cores?
bcronce - Thursday, June 5, 2008 - link
Intel claims that the new HT is improved and gives 10%-100% increase. The main issue with the P4 is that it had a double pumped alu that could process 2 integers per clock. This was great for HT since you could do 2 instructions per clock. The problem came with competition for the FPU, which there was only 1. This would cause the 2nd thread in the logical cpu to stall and thread swapping has additional overhead.You also run into the issue of L2 cashe thrashing. If you have 2 threads trying to monopolize the FPU and also loading large datasets into cache, you're cache misses go up while each thread is bottlenecked at the fpu.
techkyle - Thursday, June 5, 2008 - link
I'd like to know what AMD fans are thinking. As one myself, I'm starting to wonder if I'm going to give in and become an Intel fan.Intel implementing the IMC:
I can only say two things. One, it's about time. Two, THIEF!
Return of Hyper Threading:
It seems to me that some sort of intelligence must go in to the design of multi-core hyper threading. If two intensive tasks are given to the processor, the fastest solution would be simple, devote one core to one thread, a second core to the other. With Hyper Threading back with a multi-core twist, what's stopping one thread the first core, first virtual and the second thread on the first core, second virtual?
Another nail in the coffin:
AMD can provide no competition to high end Core 2 Quad machines. Even if the K10 line can jump up to par performance with the Core architecture, can they really expect to have a Nehalem competitor ready any time remotely close to Intel's launch? AMD can't afford to keep playing the power efficient and price/performance game.
AMD is going to be in an even worse position than when it was X2 vs Core 2 if they can't pull something out of their sleeves. Barcelona already isn't clock for clock competitive with the Penryn and now we hear that early Nehalems are 20-40% above Core 2?
If AMD's next processor flops, is it possible for them to drop desktop and server processors and still be a functioning (not to forget profitable) company? It's no longer a race for the performance crown. It's becoming a race to simply survive.
bcronce - Thursday, June 5, 2008 - link
"Return of Hyper Threading:It seems to me that some sort of intelligence must go in to the design of multi-core hyper threading. If two intensive tasks are given to the processor, the fastest solution would be simple, devote one core to one thread, a second core to the other. With Hyper Threading back with a multi-core twist, what's stopping one thread the first core, first virtual and the second thread on the first core, second virtual? "
The way Windows lists cpu is first physicals, then logicals. So in task manager the first 4, on a quad core w/ HT, will be your physical cpu and the last 4 will be you logical.
Windows, by default, will put threads on cpu 1-4 first. It will move threads around to different CPUs if it feels that one is under-taxed and another is way over-taxed.
Programmers can also force Windows to use differnt cores for each thread. So, a program can tell Windows to lock all threads to the first 4 cpus, which will keep them off of the logical. You could then allow a thread that manages the worker threads to run on the logical cpus. You would then be keeping all your hard data-crunching threads from competing with themselves and let the UI/etc threads take advantage of HT.
Spoelie - Thursday, June 5, 2008 - link
Supposedly, Shanghai (the 45nm iteration of Phenom) will be around 20% faster clock per clock over Phenom. This is what AMD said itself some time ago and not verified by an independent source. Judging by current benchmarks, this would put Shanghai at the same or slightly higher performance level of Penryn.As such, a very crude estimate is that Shanghai should be as competitive to Nehalem as K8 is to Conroe. Not a very rosy outlook so let's hope this early information is not accurate and AMD can pull something more out of its hat.
BTW, last I heard is that Bulldozer will come at the 32nm node at the earliest, since the design is supposedly too complex for 45nm. So no instant relieve from that corner. AMD will be fighting a harsh battle the coming years.
Calin - Thursday, June 5, 2008 - link
"Two, THIEF"AMD's vector processing is 3DNow!, if I remember correctly. Yet, the Intel's versions of it is are touted on its processors instead (SSE2, SSE3). Now who's the thief?
swaaye - Thursday, June 5, 2008 - link
MMX? Or, MDMX? Who copied who? Nobody, really. SIMD has been around forever.Retratserif - Thursday, June 5, 2008 - link
I really would not try and think of it as a Fan base. A majority of the OC'er and Benchmarkers use what works for what they are doing. I have owned and water cooled AMD CPU's. It was great at the time.Once Conroes came out the door swung the other way. Technology is like the ocean, it comes in waves. All waves die out. Fortunately we as the user are living it up because of Intel's success. At the same time I truly hope that AMD/ATI does something in response to the high power cpu's. If not we get what ever intel wants to give us.
There will always be to sides to each story. Since Intel is on top and unscathed, they have time to perfect chips before they go mainstream. Same way we have seen the delay in Yorkfields. There was something seriously wrong, and they had time to address it before it was in the hands of thousands of users.
Ok, I can say I am a fan.... of what ever works the best for what I do. Price/Performance/Practicallity. You take what you can afford and make it work harder for every penny you put in it.
One thing you have to keep in mind. AMD is selling more budget CPU's and integrated/onboard video PC's to large companies like Dell and HP. They are moving more aggressively into typical home PC and mobile use. Intel just does not do very well there atm. With Ati in the pocket and being pretty green on power consumption, you can get a good mobile AMD that will do everything a typical PC user will ever need for 2 years at a good price.