AMD Core Counts and Bulldozer: Preparing for an APU World
by Anand Lal Shimpi on November 30, 2009 12:00 AM EST- Posted in
- CPUs
The New Way to Count Cores
Henceforth AMD is referring to the number of integer cores on a processor when it counts cores. So a quad-core Zambezi is made up of four integer cores, or two Bulldozer modules. An eight-core would be four Bulldozer modules.

A hypothetical quad-core Bulldozer. Presumably the L3 cache would be shared by both modules.
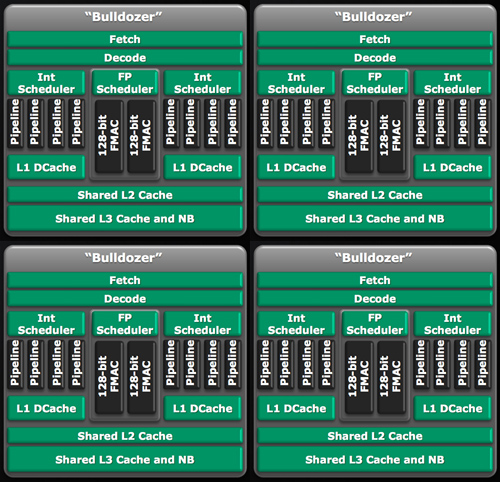
A hypothetical eight-core Bulldozer. Presumably the L3 cache would be shared by all four modules.
It's a distinct shift from AMD's (and Intel's) current method of counting cores. A quad-core Phenom II X4 is literally four Phenom II cores on a single die, if you disabled three you would be left with a single core Phenom II. The same can't be said about a quad-core Bulldozer. The smallest functional block there is a module, which is two cores according to AMD.
Better than Hyper Threading?
Intel doesn't take, at least today, quite aggressive of a step towards multithreading. Nehalem uses SMT to send two threads to a single core, resulting in as much as a 30% increase in performance:
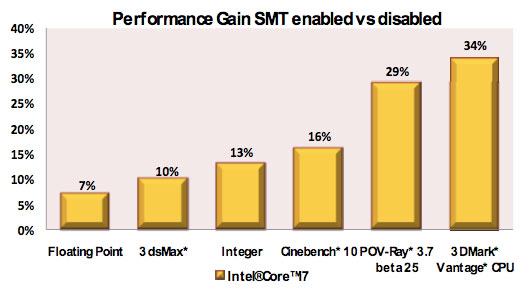
The added die area to enable HT on Nehalem is very small, far less than 5%.
AMD claims that the performance benefit from the second integer core on a single Bulldozer module is up to 80% on threaded code. That's more than what AMD could get through something like Hyper Threading, but as we've recently found out the impact to die size is not negligible. It really boils down to the sorts of workloads AMD will be running on Bulldozer. If they are indeed mostly integer, then the performance per die area will be quite good and the tradeoff worth it. Part of the integer/FP balance does depend on how quickly the world embraces computing on the GPU however...
According to AMD's roadmaps, Zambezi will use either 4 or 8 Bulldozer cores (that's 2 or 4 modules). The quad-core Zambezi should have roughly 10 - 35% better integer performance than a similarly clocked quad-core Phenom II. An eight-core Zambezi will be a threaded monster.
No GPU, for Now
The first APU from AMD will be Llano, but based on existing Phenom II cores. The move to a new manufacturing process combined with the first monolithic CPU/GPU is enough to do at once, there's no need to toss in a brand new microarchitecture at the same time.

AMD did add that eventually, in a matter of 3 - 5 years, most floating point workloads would be moved off of the CPU and onto the GPU. At that point you could even argue against including any sort of FP logic on the "CPU" at all. It's clear that AMD's design direction with Bulldozer is to prepare for that future.
In recent history AMD's architectural decisions have predicted, earlier than Intel, where the the microprocessor industry was headed. The K8 embraced 64-bit computing, a move that Intel eventually echoed some years later. Phenom was first to migrate to the 3 level cache hierarchy that we have today, with private L2 caches. Nehalem mimicked and improved on that philosophy. Bulldozer appears to be similarly ahead of its time, ready for world where heterogenous CPU/GPU computing is commonplace. I wonder if we'll see a similar architecture from Intel in a few years.








94 Comments
View All Comments
gost80 - Monday, November 30, 2009 - link
Judging apparent benefit of this architecture over Intel's can be done only if the die size per _module_ is also made available. So, how about it?Zool - Thursday, December 3, 2009 - link
The thing is that the picture in this article contains shared L2 cache and L3 cache too and its quite unclear from the picture if L2 is shared to one module or all modules.(sharing all modules 2 times with L2 and L3 would be quite useless)The bulldozer picture in the other article from anandtech http://it.anandtech.com/IT/showdoc.aspx?i=3681&...">http://it.anandtech.com/IT/showdoc.aspx?i=3681&... shows clearly that the L2 cache belongs to module.
So clearly ading 50% to the core(which is everything till L1) is much less than 2 whole cores each with its own same size L2 cache ( Nehalem has only tiny 256KB cache per core from die area reasons).
If we take whole die size with 8MB L3 cache and 1MB L2 cache per module/core (+ things like memmory controler,hypertransport core/module conects) the final die increase could end in 10-15% or even less.
Zool - Thursday, December 3, 2009 - link
So a 4 module Bulldozer core with 512KB L2 cache and 6MB L3 cache could be something like 10-15% bigger than a 4 core PhenomII with 512KB L2 cache per core and same 6MB L3 cache. For 80% more integer performance that wouldnt be bad.And about Oracle , the server cpu-s from both intel and AMD are running in ranges from few hundred dolars to over 2k dolars with minimal performance increase just more sockets suported and everyone is buying them. So i wouldnt care less for them than a fly on my window. It will end on final pricing per core for cpu not core/modul license price.
swindelljd - Wednesday, December 2, 2009 - link
I bet Oracle is salivating over the new core count technique since it is sure to create a huge surge in their revenue because they charge per core on the x86 platform.