The AMD Ryzen AI 9 HX 370 Review: Unleashing Zen 5 and RDNA 3.5 Into Notebooks
by Gavin Bonshor on July 28, 2024 9:00 AM ESTSPEC CPU 2017 Performance
SPEC CPU 2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing it is good enough. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates on our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-source compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
To note, the requirements for the SPEC license state that any benchmark results from SPEC have to be labeled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
It should also be noted that, while we've done what we can to keep testing apples-to-apples across our laptops, there are limits to how much these devices can be adjusted – and we're dealing with what are still fundamentally TDP-limited devices given their slim form factors. So these results are not strictly iso-power.
Of note, while the Intel Core Ultra 7 and Ryzen AI 9 are dialed in to a TDP of roughly 28 Watts, AMD's Zen 4/Phoenix testing vehicle, Razer's Blade 14 laptop, cannot be turned down any further than 35 Watts. So last-gen Zen has an edge in TDPs. Meanwhile, Apple M3 results come from a 2023 MacBook Pro 14-Inch, which is comparable in size and cooling capabilities to the 28W laptops, but is not strictly the same either. (AMD encourages reviewers to use the MacBook Air instead, but comparing a passively-cooled laptop to an actively-cooled run running in Performance mode hardly seems sporting)
Single-Threaded (Rate-1) Results
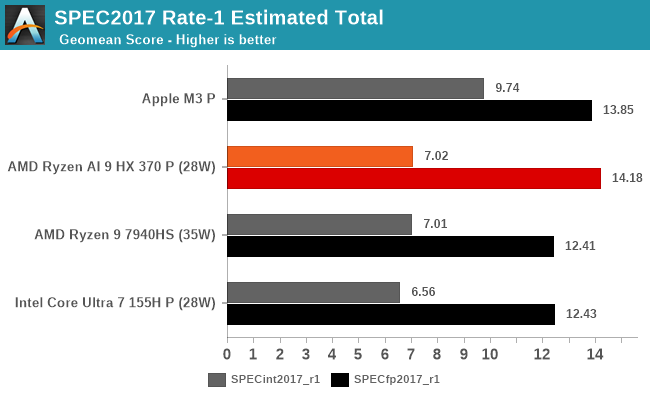
As SPEC CPU's many different sub-tests can be a bit hard to digest all at once, let's start with the geomean score of the whole suite, for a high-level look at where performance stands.
In its highest performance configuration, AMD is touting a 16% average IPC uplift for the Zen 5 architecture. But this is for the full-fat configuration with 512-bit wide SIMDs for single-cycle AVX-512 support. What Strix Point offers is a bit less, with just a 256-bit wide SIMD requiring execution over multiple cycles. The architecture still benefits from the AVX-512 instructions, but it doesn't gain the data throughput benefits. So mobile Zen 5 already starts off with a smaller potential performance uplift. Coupled with that, Ryzen AI 9 HX 370 has a peak clockspeed of 5.1GHz, versus 5.2GHz for the Ryzen 9 7940HS, so there is a slight regression here in terms of clockspeeds for the mobile parts.
All of which is to say, that these trade-offs erode some of the single-threaded performance gains the Zen 5 architecture otherwise offers, and SPEC CPU 2017's integer benchmarks seem rather unfazed. Here the HX 370 only barely edges out the 7940HS by the very slightest amount – 0.01 points – and this is not a workload where the chips' TDP differences should matter. So our first test does not find significant gains for AMD's new architecture. Still, we're treating mobile as more of a preview of things than the final word, as the desktop release should be far more enlightening thanks to the ability to better ensure platform parity, as well as throwing TDP concerns out the window altogether.
But for what mobile Zen 5 doesn't bring to the table in terms of integer performance, it looks far better in terms of floating point performance. At a geomean score of 14.18, the HX 370 is 14% ahead of the 7940HS, which is much closer to AMD's IPC claims. Among Zen 5's tweaks was allowing for a larger number of FP instructions to be in flight, and that certainly seems to be in effect here.
In fact, in floating point the HX 370 is the fastest of our mobile chips; with Zen 5, AMD moves from beating Intel in integer and tying in floating point to beating Intel all-around. We'll still see some sub-tests where the Core Ultra pulls ahead, but overall Zen 5 is a stronger architecture and it shows. Even Apple's M3 SoC gets edged out here in terms of floating point performance, which, given that Apple is on a newer process node (TSMC N3B), is no small feat. Still, there is a sizable deficit in integer performance versus the M3, so while AMD has narrowed the gap with Apple overall, they haven't closed it with the Ryzan AI 300 series.
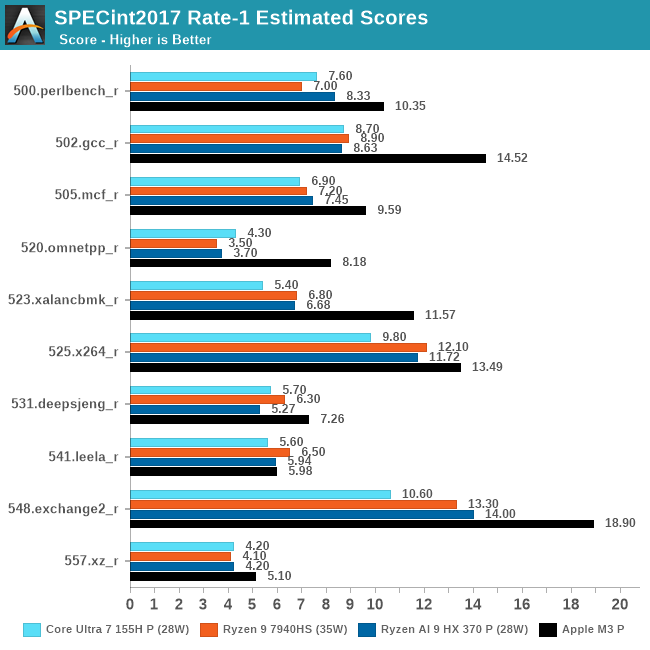
Across the complete set of integer benchmarks, the HX 370 does more often than not pull ahead of the 7940HS. However we also see more than one instance of the newer chip falling behind – 531.deepsjeng in particular stands out, where HX 370 is the slowest chip. I'm a bit curious if we're seeing some memory interplay here – the 7940HS system had DDR5, versus LPDDR5X on the HX 370 – but there's not quite enough information to draw a conclusion.
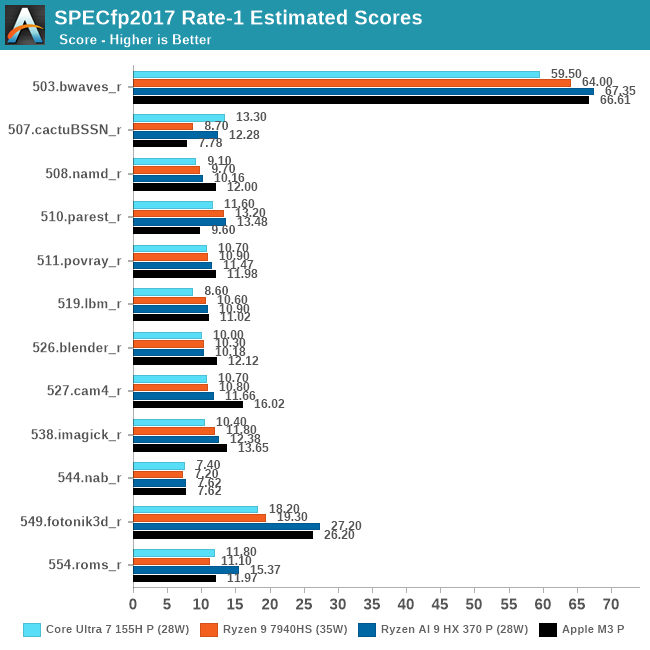
As outlined in the geomean scores, floating point tests look more favorable to AMD overall. There are no performance regressions here; the HX 370 at least marginally improves on its predecessor in every single test. And in a few, like 549.fotonik3d, it leaps ahead by 41%. AMD even clears the M3 here, which was well out of reach with Zen 4. Overall this makes Zen 5 initially look very promising for floating point workloads.
Multi-threaded (Rate-N) Results
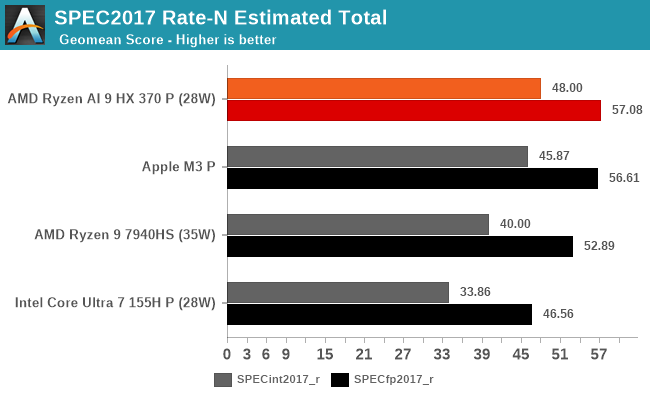
Shifting gears to multi-threaded performance, we have the SPEC CPU 2017 rate-N tests, where we run (nearly) as many copies of SPEC CPU 2017 as there are threads. Rate-N testing doesn't test core-to-core communication much, but it does push throughput hard, as upwards of 24 threads are vying for cache, memory, and other resources.
Adding a wrinkle to all of this, HX 370 (Strix Point) is the first time that AMD has put their compact Zen cores in a high-end mobile processor. This performance/efficiency core split is by no means new in the industry overall (both the M3 and Core Ultra 7 do something similar), but it's still a big shift for AMD's flagship mobile chips, as achieving peak multithreaded performance is now not about saturating 8 performance cores, but saturating 4 performance cores and then another 8 efficiency cores on top of that.
With Rate-N being TDP-limited in a laptop, this is less a test of architectural throughput than it is overall efficiency, and not surprisingly, it paints a very different picture from rate-1 results – and one that's very favorable to AMD. Overall, the HX 370 is the top chip, not only meaningfully improving on the 7940HS in both integer and FP workloads, but even edging out Apple's M3. The 4 additional efficiency (Zen5c) cores is likely playing a major role here versus Apple, but given that all of these devices are similarly power constrained, AMD is still getting more work done overall despite those conditions. In SPEC CPU 2017, at least, it looks like a good trade-off.
Interestingly, despite AMD's flat integer performance in ST results, the HX 370 sees its biggest gains under MT integer workloads, improving on the 7940HS by 20%. Even with their lower peak clockspeed, those additional Zen5c cores are doing a lot to boost performance here. Meanwhile, MT floating point performance is just 8%, likely coming as a result of TDP limitations. While we don't have a detailed power breakdown available on these mobile platforms, if AMD's FP performance gains come at a cost of higher power consumption per core, then that would in turn bottleneck performance under these heavy MT workloads.
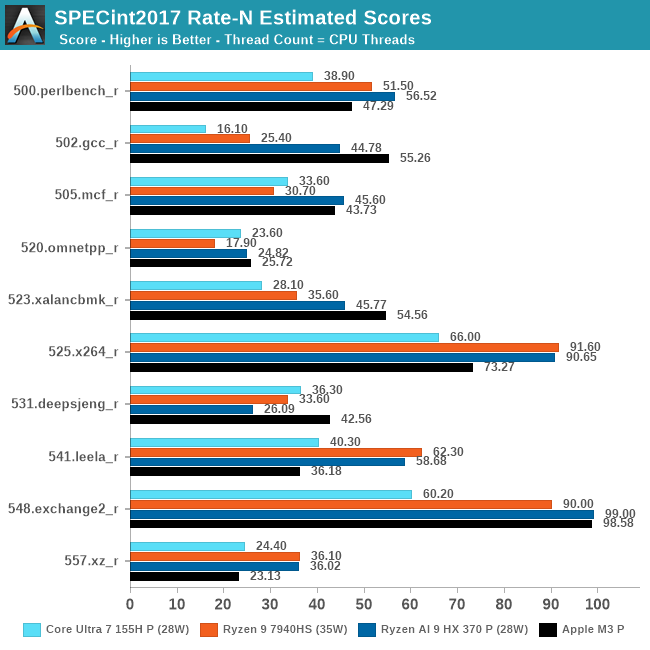
Breaking down our results to the individual benchmarks, the HX 370 significantly improves upon its predecessor in several tests, including 502.gcc, 505.mcf, and 520.omnetpp. Especially compared to the more anemic gains in these benchmarks in single-threaded mode, these benchmarks show the performance advantage of a larger number of efficiency cores versus the 7940HS's flat 8 performance core configuration. Still, these are some regressions; 531.deepsjeng performance still drops here, and the extra cores aren't doing anything to help out 525.x264 performance.
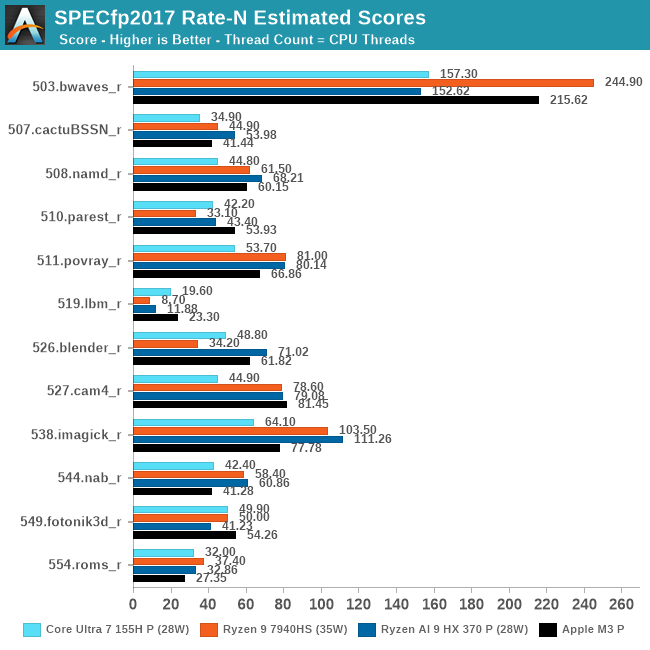
Under multi-threaded floating point performance, there are again some big gains, such as in 526.blender and 519.lbm, as well as smaller gains in the likes of 538.imagick. Meanwhile the most surprising result comes in 503.bwaves, which sees a significant performance regression versus the 7940HS. We've run this test several times and it doesn't seem to be a fluke; bwaves just doesn't seem to like those compact Zen 5 cores very much. Which makes these results a great showcase for the trade-offs involved in using a heterogeneous core selection – adding weaker cores can help a lot of workloads, but there will always be some workloads that just want as many performance cores as they can get their hands on.








72 Comments
View All Comments
Dante Verizon - Sunday, July 28, 2024 - link
Why are you comparing an ultra-thin design to a CPU with PL2 at almost 90w? The notebookcheck tests show that the Zenbook runs up to 50% slower than the ProArt chassy.Ryan Smith - Sunday, July 28, 2024 - link
Sorry, which notebook are you referring to? We have multiple Zenbooks here.Terry_Craig - Sunday, July 28, 2024 - link
He's probably talking about the Zenbook in the review: https://www.notebookcheck.net/Asus-Zenbook-S-16-la...Strix performs much worse on the Zenbook than inside the ProArt, probably due to more aggressive power and temperature management.
Ryan Smith - Sunday, July 28, 2024 - link
It's definitely not a high performance chassis, despite being 16-inches. The default TDP is just 17 Watts; AMD asked reviewers to bump it up to 28W.But this is what AMD sent out for review. Given the wide range of laptop TDPs out there, these review unit laptops can never cover the full spectrum. So it's more a reflection of what power level/form factor the chipmaker is choosing to prioritize in this generation.
The Hardcard - Sunday, July 28, 2024 - link
What is the 90W laptop in this review? The other laptops are listed at 28W and 35W here. I did not see any indication of the power specifications of the ProArt on the other site, just some numbers provided. I strongly suspect that laptop is running at top TDP, 45-54W.So, like, a different comparison.
Terry_Craig - Sunday, July 28, 2024 - link
https://www.notebookcheck.net/AMD-Ryzen-9-7940HS-P...Depending on the model, the 7940HS goes up to 100w.
The Hardcard - Monday, July 29, 2024 - link
But, is the 7940HS pulling 100w in this review instead of the reported 35w? Otherwise,, what is the point of the complaint?https://www.ultrabookreview.com/69005-asus-proart-...
The HX 370 is in a different chassis pulling 80w sustained. Does that make the 35w vs 28w happening here more fair? I mean, if what the chips can draw elsewhere somehow matters here at all?
eastcoast_pete - Monday, July 29, 2024 - link
It matters if one wants to look at the maximum performance possible, regardless of power draw. But, in addition to what Ryan wrote, the attraction of the HX Series to me is the strong performance at lower power draws. I would have actually liked to see performance comparisons at 17 W, which IMHO is of special interest in such thin and light notebooks. The higher end (> 50 W) will be if interest for Strict Halo, which as far as I can tell is supposed to take on notebooks with smaller dGPUs.ET - Sunday, July 28, 2024 - link
From the benchmarks here, the 370 looks somewhat disappointing on the CPU front, with some losses to 8 cores Zen 4. A hybrid architecture is always a problem. I wonder if future scheduling changes will help or if the small 8MB L3 for the Zen 5c cores is a problem that can't be overcome.The new GPU however looks like a good upgrade over the previous gen.
nandnandnand - Sunday, July 28, 2024 - link
It's hybrid with different cache amounts, but it's also two CCXs instead of one after 3.5 generations of simple 8-cores. It's hard to say what's screwing it up.Phoronix's review was more positive for the CPU. The main benefit is power efficiency:
https://www.phoronix.com/review/amd-ryzen-ai-9-hx-...
The reviews I looked at didn't look too good for the GPU. Maybe it will do better with more power, but what it really needs is memory bandwidth. Hopefully AMD brings some Infinity Cache to its mainstream 128-bit APUs in the future.