SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
Thread Machine Gun
Besides hard-to-predict branches and high memory latency, server applications on MP systems also get slowed down by high latency network communication and cache coherency (keeping all the data coherent across the different caches; read more here).
To summarize, the challenges and problems that server CPUs face are:
Memory latency is by far the worst problem, causing a typical server CPU to be idle for 75% of the time. So, this is the first problem that the SUN/Afara engineers attacked.
The 8 cores of the 64 bit T1 can process 8 instructions per cycle, each of a different thread, so you might think that it is a just a massive multi-core CPU. However, the register file of each core keeps track of 4 different active threads contexts. This means that 4 threads are "kept alive" all the time by storing the contents of the General Purpose Registers (GPR), the different status registers and the instruction pointer register (which points to the instruction that should be executed next). Each core has a register file of no less than 640 64-bit registers, 5.7 KB big. That is pretty big for a register file, but it can be accessed in 1 cycle.
Each core has only one pipeline. During every cycle, each core switches between the 4 different active threads contexts that share a pipeline. So at each clock cycle, a different thread is scheduled on the pipeline in a round robin order; to put it more violently: it is a machine gun with threads instead of bullets.
In a conventional CPU, such a switch between two threads would cause a context switch where the contents of the different registers are copied to the L1-cache, and this would result in many wasted CPU cycles when switching from one thread to another thread. However, thanks to the large register file which keeps all information in the registers and Special Thread Select Logic, a context switch doesn't require any wasted CPU cycles. The CPU can switch between the 4 active threads without any penalty, without losing a cycle. This is called Fine Grained Multi-threading or FMT.
If a branch is encountered, no branch prediction is performed: it would only waste power and transistors. No, the condition on which the branch is based is simply resolved. The CPU doesn't have to guess anymore. The pipeline is not stalled because other threads are switched in while the branch is resolved. So, instead of accelerating the little bit of compute time (10-15%) that there is, the long wait periods (memory latencies, branches) of each thread is overlapped with the compute time of 3 other threads.
So, one core gets an IPC of about 0.7, which is very roughly twice as good as a big 3-way superscalar CPU with branch prediction and big OOO buffers would do, and it takes less chip logic to accomplish.
Besides hard-to-predict branches and high memory latency, server applications on MP systems also get slowed down by high latency network communication and cache coherency (keeping all the data coherent across the different caches; read more here).
To summarize, the challenges and problems that server CPUs face are:
- Memory latency, load to load dependencies
- Branch misprediction
- Cache Coherency overhead
- Keeping Power consumption low
- Latency of the Network subsystem
Memory latency is by far the worst problem, causing a typical server CPU to be idle for 75% of the time. So, this is the first problem that the SUN/Afara engineers attacked.
The 8 cores of the 64 bit T1 can process 8 instructions per cycle, each of a different thread, so you might think that it is a just a massive multi-core CPU. However, the register file of each core keeps track of 4 different active threads contexts. This means that 4 threads are "kept alive" all the time by storing the contents of the General Purpose Registers (GPR), the different status registers and the instruction pointer register (which points to the instruction that should be executed next). Each core has a register file of no less than 640 64-bit registers, 5.7 KB big. That is pretty big for a register file, but it can be accessed in 1 cycle.
Each core has only one pipeline. During every cycle, each core switches between the 4 different active threads contexts that share a pipeline. So at each clock cycle, a different thread is scheduled on the pipeline in a round robin order; to put it more violently: it is a machine gun with threads instead of bullets.
In a conventional CPU, such a switch between two threads would cause a context switch where the contents of the different registers are copied to the L1-cache, and this would result in many wasted CPU cycles when switching from one thread to another thread. However, thanks to the large register file which keeps all information in the registers and Special Thread Select Logic, a context switch doesn't require any wasted CPU cycles. The CPU can switch between the 4 active threads without any penalty, without losing a cycle. This is called Fine Grained Multi-threading or FMT.
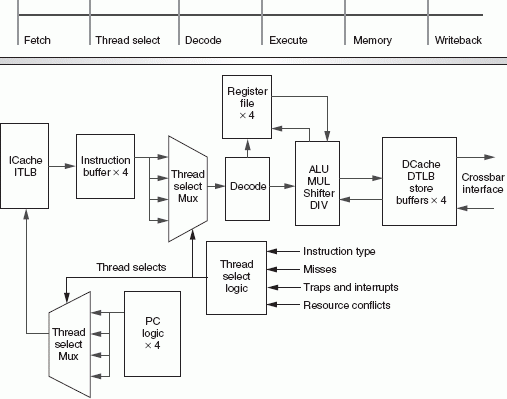
Fig 3: The SUN T1 Pipeline. Source:SUN [1].
If a branch is encountered, no branch prediction is performed: it would only waste power and transistors. No, the condition on which the branch is based is simply resolved. The CPU doesn't have to guess anymore. The pipeline is not stalled because other threads are switched in while the branch is resolved. So, instead of accelerating the little bit of compute time (10-15%) that there is, the long wait periods (memory latencies, branches) of each thread is overlapped with the compute time of 3 other threads.
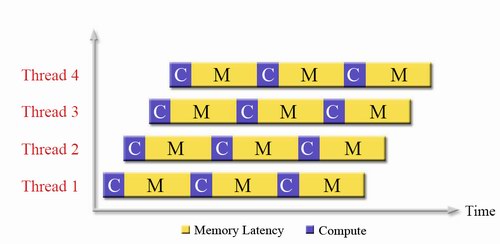
Fig 4: Fine Grained Chip Multi-threading in action. Source:SUN.
So, one core gets an IPC of about 0.7, which is very roughly twice as good as a big 3-way superscalar CPU with branch prediction and big OOO buffers would do, and it takes less chip logic to accomplish.








49 Comments
View All Comments
Brian23 - Saturday, December 31, 2005 - link
While it's true that HT helps fight this issue, it's not the complete solution. Sun's approach is much better.Betwon - Thursday, December 29, 2005 - link
How terrible!The single issue pipeline/core!
Poeple always complains that: we fails to find the enough threads(2 or 4 threads) in the most apps for the multi-thread CPU.
Now, it is very difficult to find a app(8X4=32 threads parallel well).
Calin - Tuesday, January 3, 2006 - link
It is hard to find parallelism in one application so you could run it well on two cores. However, if you use 32 applications, you can run it very well on 32 cores.JarredWalton - Thursday, December 29, 2005 - link
Most servers don't run a lot of single-threaded apps, or if they do they run many instances of the single-threaded app/process at the same time. This is clearly not a chip designed for all markets, but it is instead focused on doing very well in a niche market.thesix - Thursday, December 29, 2005 - link
Johan,Nice article!
A small point: I don't think it's correct to refer Sun Microsystems Inc. as 'SUN', it should be 'Sun'.
Even though it originally stands for Standford University Network, 'SUN' is no longer the semi-official name, AFAIK.
When T1 based system is announced, I was hoping to see some independent benchmarks from Anandtech, especially the MySQL one you guys used to benchmark the server performance.
I know it's not scientific, and SPEC is as good as it gets, still I am curious :-)
Have you guys considered using T1000/T2000 to power Anandtech, given it's so cheap and designed for webserver type of workload?
That would be a good win-back story for Sun, I remembered you guys migraded from Sun Ultra boxes to PC server several years ago :-)
steveha - Thursday, December 29, 2005 - link
Why drop the opteron from the Specweb2005 results? Did it destroy the T1?stephenbrooks - Monday, January 2, 2006 - link
We think we should be told.NullSubroutine - Thursday, December 29, 2005 - link
How do these price? It seems the performance per watt is very good, but what if the cpu and the platform costs more?I might have missed it, but what was the die size?
icarus4586 - Thursday, December 29, 2005 - link
I'm assuming that should read,
I wouldn't guess Sun is using IBM technology or marketing terms.
JohanAnandtech - Thursday, December 29, 2005 - link
As thesix already commented (thanks :-), hypervisor is indeed IBM talk. AFAIK, IBM was first.